
英语原文共 5 页,剩余内容已隐藏,支付完成后下载完整资料
基于基音同步算法和重采样技术改变基音达到变声效果
Allam Mousa
摘要:声音变换在工业和商业领域中声音变换有很多的应用。这篇文章着重强调使用基音同步叠加技术和重采样技术将声音从原说话者的音频转换到目标说话者的音频。重采样的目的是为了实现语音的变调不变速效果。这篇文章考虑的是一些阿拉伯人说话的声音,在检测确定的元音声音时结果中的,男性和女性的声音会有相应的拉伸或者压缩。基音变换的结果在这里呈现,对单帧和语音的全切分同样也进行研究。
关键词:声音变换,psola,移调,重采样,SIFT
1介绍
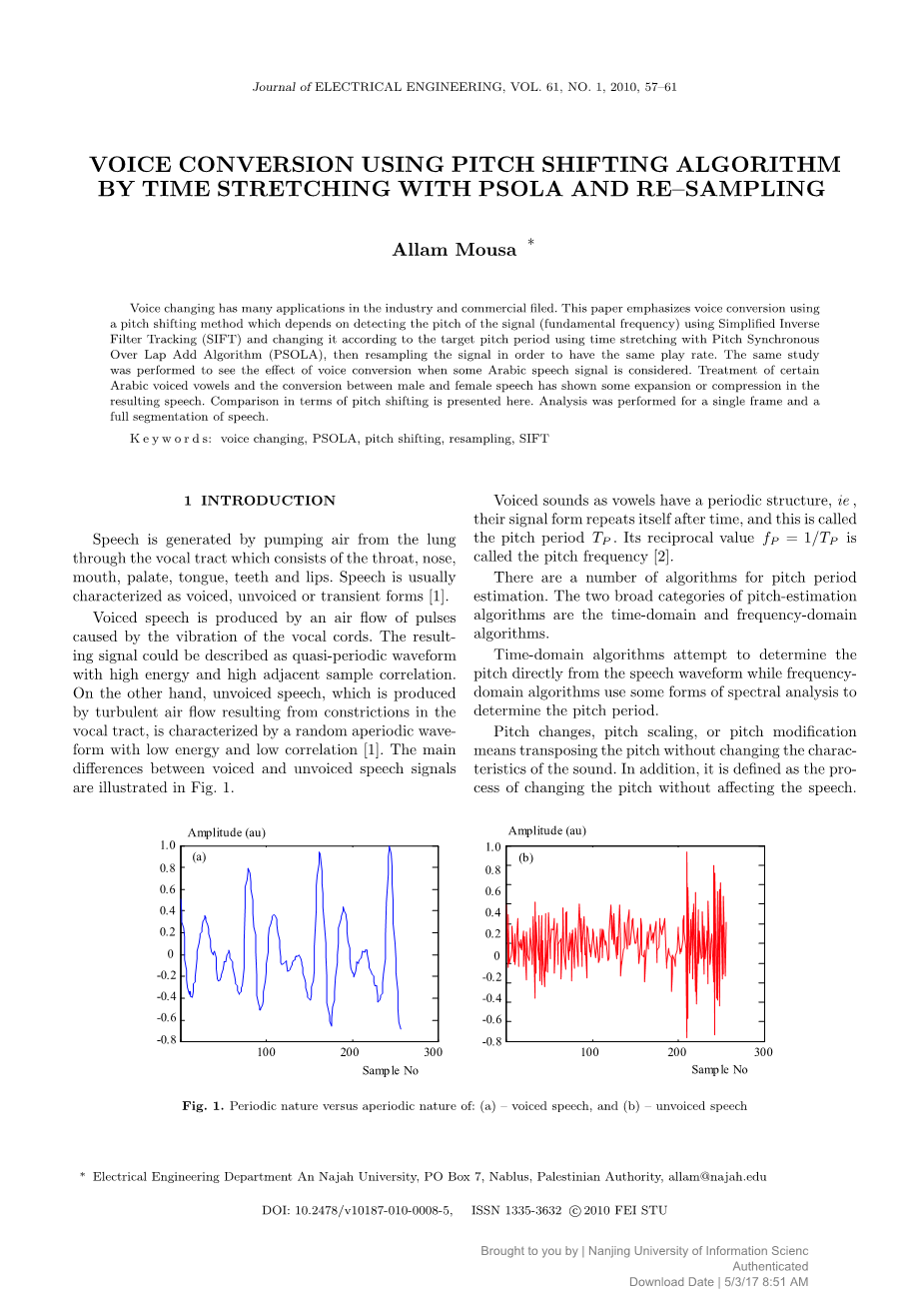
语音是由肺的空气泵产生的通过声道(声道组成的喉咙,鼻子,嘴巴,上颚,舌头,牙齿和嘴唇)产生的空气震动。语音通常以浊音,清音或者其他短暂形式的声音为特征[1]。
浊音是由声道的肌肉引起的空气震动产生的,其结果信号可以用准周期信号来描述,并且其样本伴随着高能量且为高度相关。
另一方面,清音由声道收缩造成的乱流产生的声音,其以低能量低相关性的非准周期波形为特征。清音和浊音的主要区别在图1中可以得到证明。
图1 a图为周期信号的波形图, b图为非周期信号波形图
听起来像元音的浊音有周期性的结构,它们的信号的波形在经过一段时间之后还会重复,这个时间就叫做周期T,周期的倒数即FP=1/T被称作频率[2]。
对基音周期的估计有很多的算法,其中最主要的两种就是在时域和在频域中的算法。时域中的算法致力于通过声波来直接确定音调,而频域中的算法使用一些光谱分析去确定基音周期。基音变换,基音变调或者基音模拟意味着改变基音却不使其丢失声音的本质特征。除此之外,它还被定义成改变声音却不影响声音的过程。
音高变换在语音转换的过程中是一个重要的算法,其在训练外语工作者的业务水平和在当今电影产业后期的制作的过程,例如配音,对声音的剪辑重塑等过程中得到了广泛的应用。除此,基音变换在将文本文字转化成可以被直观听到的口语声音的过程也发挥着举足轻重的作用。此外,语音变换尤其在帮助失聪和失明人士的能力恢复的领域和语音密码验证和安全等重要信息科技和国防领域中不可或缺。
2 使用基音同步叠加实现语音的变换
语言变形的声音的转化是有明显的不同的。在前一个案例中,信号源和目标信号应该有效地相似且要合理对其,在获得新信号之前应该进行插值。在后一个算法案例中,信号源与目标信号的关系通过两个不同说话者大量的话语中得以联系,这个随后就会将原说话者的声音转变为目标说话者的声音。
如果目的是改变声音,则其中一个方法就是去改变声音的基音,这就需要使用基音同步算法此类特定的技术去实现基音的变化。
2.1 基音变换
这个基音周期是用来是一些声音比其他的声音更加尖锐,在特定的时间里震动的次数决定了基音周期。声音的变化率叫做频率,频率越高,声音的基音越高。基音转化算法的目的在于使基音发生变化的同时却不会改变其重复率。基因变化可以通过基音同步叠加和重采样操作来实现。
2.2 psola
Psola 是基于一种将信号分解成许多基本的波形额叠加,在这个过程中信号的基音周期的综合与叠加再次重组为信号,基音同步叠加技术直接作用于信号的波形而不会使用任何类型的模型,因此不会损失信号的任何细节[4]。 基音同步叠加算法有许多,如时域基音同步叠加,频域基音同步叠加和线性可预测基音同步叠加。时域基音同步叠加由于其其运算效率高而被广泛运用,但是其他的算法类型因为在合成信号的频谱包络中的独立性故是实现音高变化的适当方法[5]。
基音变换在语音转换的过程中是一个重要的算法,其在训练外语和电影的配音过程中得到了广泛的应用,除此,基音变换在将文本文字转化成口语过程也密切相关。尤其在帮助失聪和失明人的领域和说话者的验证和安全中有很多的应用
2.3时域里的基音同步叠加算法
时域基音同步算法被提出时允许基音对给定的声音信号进基音变换而不会改变声音的时空特性。时域基音同步叠加包括下面的三个步骤:
- 分析步骤,在此过程中,原始声音信号一开始就被分解成独立的且叠加的短的分析信号。短的信号可由数字语音波形X(N)与一系列的基音同步窗HM(N)相乘得到,就如公(1)所示
XM(N) = HM(TM minus; N)X(N) , (1)
2.窗口通常是hanming类型,主要是集中于连续的瞬间TM,称作基音标注点。这些标注点信号的浊音部分和清音的连续速率的位置
3.修改步骤,每一个框架都是根据目标来进行修改。合成的步骤在操作过程中以至于这些部分可以通过基音同步叠加的方式进行重组。
时域内基音重组的优点是:
易于实施
当给定的语音信号音高间距较小时被使用,能得到良好的效果。
可以简单地通过时间缩放和采样率转换的方法实现在时域里的间距放缩。
2.4用基音同步叠加算法和重采样技术实现声音转换
基音的时间拉伸和重采样简单地涉及到对之前描述的时间在psola算法下进行处理并通过重采样目的是返回其原来声音的特质。通过基音拉伸然后重采样就会创造出较高的基音,如果折叠就会产生较低的基音。也有许多其他的基音变换的手段比如延迟线调制或者共振峰的保存[7]。在图2中展示了基音从(t)到(t)变化的过程。
图2 基音同步叠加算法前提下共振峰对比
2.5基音检测
基音的周期通常定义为两个连续的声门激励之间。基音检测在很多语音处理任务和应用的过程中十分必要。这个包括将语音信号分为浊音和清音这两个语言区[8]。
由于语音产生过程的机械化基音可能并不是一个直接决定的过程,因此还有一些其他的基音检测的算法例如:
时域分析比如自动相关性的方法,平均幅度不同功能,
频域分析比如倒谱,
其他的例如最大可能性法,简单逆滤波器跟踪法,神经网络方法。更多的细节和研究可以参考[8],这个工作已经考虑到很多基音决定算法比如简单逆滤波器跟踪法,梳状滤波器能量最大化,光谱累加,最佳时间相似,二进小波变换等。
这个算法被用来检测原信号和目标信号的的基音是一个简单逆滤波器示踪法,这种方法起初被Markel使用并发展,起初被Markel使用的简单逆滤波器算法的框图如图3所示。
图3. 简单逆滤波器算法的框图
3 模拟结果
使用psola和重采样的的声音拉伸基音变换技术在图4中应用于一名女性讲话的声音中。其目的是减少这个信号基音的频率,新的基音频率与原来的基音频率之比大概是0.75,其倒数是重采样新的信号因子1/0.75=1.33.
在图5中已经完整地展现除了语音变换的这一全过程,其标明这个变换后的信号与原信号几乎有一模一样的形状和相同数量的采样,这主要得益于其过程中使用的重采样技术。为了获得相同的播放速度,一个主观的测试在一个新的信号里被实施,我们可以清晰地看到一个男生说的话的内容与之前的女生完全类似,在谱图6中我们可以清晰观察得到
为了清晰地观察小数据信号时,图7展示了原信号两帧的内容,清晰地表现了一个浊音信号之前和变换后的周期,结果和预期效果相同。
图4 拉伸前的女声信号 图5拉伸后的女声信号
图6 采样前后信号对比 图7原始信号两帧内容图谱
频域中可能更加清晰地反映出这些变化。这些帧的光谱会在图8中显示出来,在
图中我们可以看到共振峰频率由于基音变换已经发生了向左的位移。事实上,整个的频谱都发生了左移的现象。一些检测,如共振峰修正已经被应用到结果声音的质量提高领域里去。
整个声音信号基音周期的改变效果在图9中已经有所展示,信号的每一个独立的包络也都有体现。我们可以很明显地得到这个结论,清音的基音周期已经被正确地转化成我们预期地那种低频率的声音。
频域中可能更加清晰地反映出这些变化。这些帧的光谱会在图8中显示出来,在图中我们可以看到共振峰频率由于基音变换已经发生了向左的位移。事实上,整个的频谱都发生了左移的现象。一些检测,如共振峰修正已经被应用到结果声音的质量提高领域里去。
整个声音信号基音周期的改变效果在图9中已经有所展示,信号的每一个独立的包络也都有体现。我们可以很明显地得到这个结论,清音的基音周期已经被正确地转化成我们预期地那种低频率的声音。
图8 帧的光谱图 图9 基音信号改变效果图
一些阿拉伯元音可能会有一些独特的地方比如A 和kh,因此,当声音转化被应用时,同时也需要一个独特的方案。一个典型的阿拉声音ALI在图10中有所展示,这个女性说话者的声音中在元音A的发音时会有所加重。
图10 阿拉伯声音波形 图11 变换后的波形效果
基音变换在整个语音中的应用在图11中显示已经达到了预期的效果。在对数据的进一步研究和观察中我们在图12中得出一个结论,即究竟有多少基音被变换和这些信号如何被变换的。
在图13中清晰地显示出了初始信号和变换后的信号在整个共振峰频率都被左移,所有的高频内容都被压缩到较低的振幅。
图12 基音变换信号前后对比 图13 共振峰左移对比图
4 讨论和总结
基于基音同步叠加和重采样技术实现的基音变换从而实现声息的变换作如下讨论
基音被检测目的是为了确定原信号和目标信号的基音频率,然后声音被从女性的声音转化成男性发出的声音,这个预期的结果表明当将女性声音转化成男性声音的时候基音的频率会减少而信号必须要拉伸,相反,当将男性声音转化成女性声音时,基音的频率会增加而信号必然会有所减弱。当这个算法被用到阿拉伯或者英语语音时产生的效果是类似的。
参考文献:
- KONDOZ, A. M. : Digital Speech, Coding for Low Bit Rate Communication Systems, Wiley, 2004.
- JELINEK, M.—ADOUL, J.-P. : Frequency-Domain Spectral Envelope Estimation for Low Rate Coding of Speech, icassp, 1999.
- PFITZINGER, H. R. : Unsupervised Speech Morphing between Utterances of any Speakers, Proceedings of the 10th Australian International Conference on Speech Science amp; Technology, Syd-ney, December 8-10, 2004.
- SCHNELL, N. ET AL : Synthesizing a Choir in Real-Time using
Pitch Synchronous Overlap Add (PSOLA), http//www.ircam.fr, dated 10/Sep/2006.
- JAU-HUNG CHEN—YUNG-AN KAO : Pitch Marking Based on an Adaptable Filter and a Peak-Valley Estimation Method, Computational Linguistics and Chinese Language Processing 6
No. 2 (Feb 2001), 1–12.
- MARTIN, H.—GERNOT, K. : Poincare Pitch Marks, Speech Communication 48 (2006), 1650–1665.
-
ARFIB, D.—VERFAILLE, V. : Driving Pitch-Shifting and Time-Scaling Algorithms with Adaptive and Gest
剩余内容已隐藏,支付完成后下载完整资料
资料编号:[26690],资料为PDF文档或Word文档,PDF文档可免费转换为Word
课题毕业论文、外文翻译、任务书、文献综述、开题报告、程序设计、图纸设计等资料可联系客服协助查找。

