
英语原文共 10 页,剩余内容已隐藏,支付完成后下载完整资料
一种粗粒度FPGA架构的高性能FIR滤波
1.摘要
本文介绍了一种粗粒度的FPGA,专门针对高性能的架构对有限脉冲响应(FIR)进行过滤。 所提出的架构提供具有高性能的DSP处理器的灵活性和高面积效率,类似一个定制的ASIC设计,同时允许所有的基本FIR设计参数,包括系数精度,都可以进行配置。 以前的研究已经表明FPGA可以提供高性能的器件来取代DSP处理器。本文中科学性的比较表明,所提出的架构的性能和面积效率与传统的很庞大的尺寸和构架的滤波器一样。
1.1关键词
现场可编程门阵列(FPGA),架构,有限脉冲响应(FIR)滤波,数字信号处理(DSP)
2.引言
数字信号处理系统通常在计算上密集很大,需要巨大的I / O带宽。为了满足DSP系统的性能要求,许多定制硬件系统都依赖于ASIC。然而,ASIC固有的不灵活性和开发性让这种系统变得价格昂贵并且处理耗时。DSP处理器提供灵活,低成本的替代方案,但是性能有限制。FPGA提供了保持灵活性的第三种替代方案,即DSP处理器通过重新编程的方式,并且它提供性能水平明显高于DSP处理器。 由于灵活性和性能特性,FPGA已被考虑实现DSP系统。 最近的一项研究发比之DSP处理器,信号处理的幅度性能有一个顺序性地提升,可能就是基于FPGA的DSP系统。 其他专用系统,如可重构的Splash 和PAM 系统也有已使用FPGA实现定制应用程序。基于可编程架构的DSP系统设计对于低功耗也进行了研究。
在本文中,我们针对在许多DSP系统中广泛使用的FIR滤波器进行讨论。 我们提出可以排列成各种各样的专用电池拓扑提供针对的FPGA架构FIR滤波。 我们基于细胞的方法的目标是提供允许所有基本FIR的架构滤波器设计参数要配置,但提供定制设计ASIC的性能和面积效率方法。
在下一个部分将介绍FIR滤波和讨论提供上层的两种定制设计方法和降低绩效和实施准则区。 第4节首先介绍基于细胞的方法描述8位精度的基本单元,然后描述可以用于8,16或更强的细胞24位精度。 第5节比较了性能和几种尺寸的基于单元的实现的布局区域与第2节讨论的两种定制设计方法第6节结束文件。
3.自定义方法
3.1概述
在数学上,采样数据FIR滤波器可以是以卷积和表示。
y(n)= x(n) x(n-1) hellip; x(n-N) (1)
其中y(n)是样本n处的滤波输出,x(n)是在样本n处的输入,hi是脉冲响应系数,N是滤波器的顺序。一个直截了当实现FIR滤波器的方法是直接评估卷积总和中的乘积之和。 这个方法需要存储最新的N个样本输入,每个样本乘以相应的过滤器系数,并对产品进行总结。 图1显示了一种4抽头FIR滤波器的框图,每个滤波器抽头由延迟元件,加法器和乘法器组成。
图1 4抽头FIR滤波器
FIR滤波器特性,如通带纹波,阻带衰减和转换带宽取决于系数的值,系数的精度和输入数据,以及过滤器的长度(个数抽头)。 截止频率取决于采样率,或输入样本进入过滤器的速率。 因此,其他比用于滤波器系数的实际值,那里只有三个基本的设计参数:精度,过滤长度和采样率。 如下文所述,我们的方法允许重新配置这些设计参数中的每一个。
参考图1所示的FIR实现作为抽头延迟线结构。 但是,很多实现存在FIR滤波的拓扑。 在另一种选择实施时,可以放置延迟元素在水龙头的加法器之间。 此外,如果系数为已知是对称的, = ,通常是这种情况在线性相位滤波器中,只需要一个乘法器每两个抽头,减少乘数的数量因子二。 每隔一段时间也是如此系数为零,允许乘法器和加法器每隔一个单元结构被淘汰。
为了本文的目的,我们不会假设任何一个滤波器系数的先验知识,除了它们精确。 因此,所有以下FIR滤波方法使用图1所示的抽头延迟线方法。对于定制设计的FIR滤波器,有两种方法它们提供了不同FIR实现之间性能和硬件要求比较的指导原则:平行和顺序。 并行方法寻求最大的性能,而不受硬件限制。相比之下,顺序方法最小化了硬件要求同时产生最差的性能。以下将讨论两种方法部分。
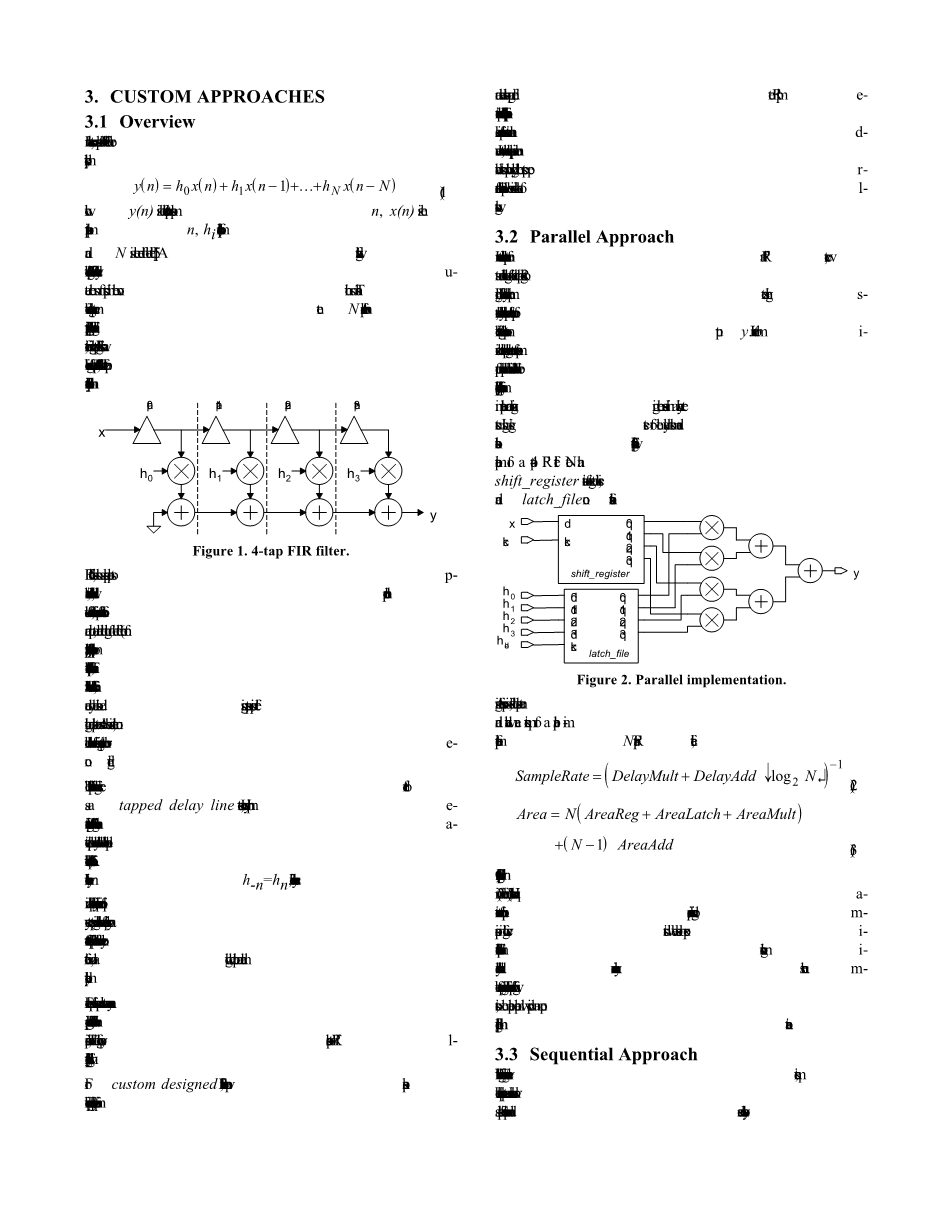
3.2并行方法
为了最大化FIR滤波器的采样率,我们必须减少关键路径的长度。 参考如图1所示,如果延迟元件被实现为寄存器,那么明确的关键路径是从输出的第一个注册到样品输出y。 为了最小化关键路径长度,计算量并行执行应最大化。 这可以通过执行所有系数乘法来实现并行并在二叉树中组织加法器结构体。 使用延迟元素寄存器和锁存器存储系数,图2显示了并行实现4抽头FIR滤波器。 注意shift_register包含四个串联的寄存器,而latch_file包含四个锁存器。
图2 并行实现
假设系数精度是固定的,采样率和硬件区域要求并行实现对于N抽头FIR滤波器,
SampleRate =1/(DelayMult DelayAddtimes;[]) (2)
Area= N(AreaReg AreaLatch AreaMultN) (N-1)times;AreaAdd (3)
当然,我们忽略了注册设置和保留时间(2)和(3)中的互连区域。 但是,这些方程式对于我们的目的来说是足够的,因为所有的设计比较以下部分将基于实验数据。 采样率反对数倒数并且硬件面积随着单元结构数量呈线性增加。 因此,在以下的比较中部分,平行方法将提供一个上限绩效和实施领域的指导方针。
3.3顺序方法
为了最小化硬件面积要求,顺序方法寻求重用同样多的硬件尽可能。 由于乘法器和加法器面积较大,因此只使用其中之一。 计算(1)中的每个产品项依次加到累积金额中加法器/寄存器组合。 但是,为了顺序选择要乘以的输入样本和系数,需要三态缓冲器和简单的控制逻辑。图3显示了a的顺序执行4抽头FIR滤波器。 控制器简单地从0到(N-1)并启用下一个三态缓冲区,这允许shift_register和latch_file的下一个q输出在每个计数乘以。 在每个第0个计数,dshift是激活以移动数据样本,零被激活将累加器的寄存器设置为零。
图3 顺序执行
虽然这种方法的关键路径比并联方式,电路必须循环N次产生单个输出样本。 因此,样品速率和硬件面积的N抽头顺序执行是,
SampleRate NDelayBuffer DelayMult DelayAdd()
Area =N( AreaReg AreaLatch AreaBuffer) []xAreaControl AreaMult AreaAdd AreaReg
(5)
再次注册建立和保持时间以及互连地区被忽视。 AreaControl的值是2抽头FIR控制电路的区域。该区域随着抽头数增加的因子增长。 当然,这是一个粗略的近似,但它是适合我们的目的。
采样率现在与滤波器抽头的数量增加。 因此,表现的顺序方法比这更快地降级的并行方法。 顺序方法的区域随着N线性增加。然而,由于乘数并且加法器区域不随N和缓冲区而改变面积不大,面积平行的方法比顺序方法快得多随着N增加。 因此,顺序方法提供了一个降低性能和实施的准则区。
4.基于细胞的方法
基于细胞的方法的目的是提供一种具有FIR滤波应用的FPGA架构性能和实施方面类似定制电路。 具体来说,架构就是旨在提供高性能的定制并行方法或区域效率(在滤波器抽头方面每单位面积)。 此外,该架构被设计为允许电路容易配置为在这两个极端之间或之间的设计点。以下部分讨论基本的可重新配置满足这些目标和服务的细胞作为增强型可重新配置的介绍。
4.1基本可重构单元
基本单元是顺序实现的简单扩展的4抽头FIR如图3所示允许在启用的拓扑中连接单元滤波器抽头的数量和数据采样率要被用户配置。图4显示了基本单元格。 我们猜测滤波器系数和输入采样是8位单一的精确。
图4 基本单元
图4的单元被设计成在一个之间实现和四个滤波器抽头,取决于ntap的值控制块上的输入。 为了延长顺序已经添加了实现,复用和注册并且控制块已经被改变为包括一些附加功能。 添加多路复用器允许一个初始化值将被加载到累加器寄存器中产品的总结开始。 这个复制和添加连接到xnext输出的寄存器允许将细胞串联放置以产生细胞链实现具有大量抽头的FIR滤波器。 这个将在稍后详细讨论。 我们先来看看单个电池的操作。
表1显示单个单元格的操作,如果单元格是用于实现四个抽头(ntap = 3)。 假设每一行该表是一个时钟周期和一个新的数据样本,标记为d0,d1等,每四个时钟到达输入x一次。 也,假定yprev输入的值为零,那么滤波器系数h0至h3已经被加载到latch_file中。 表1列出了持有的值shift_register,控制块的选择输出上的值以及输出y。 acc_reg列表示由16位累加器寄存器保存的值。
表1.单电池操作(参照图4)
如表所示,四种产品的总和成为在第四个时钟边缘之后可用。 这个值可以作为输出传递给用户或输入到yprev的链中的下一个单元格。 ntap输入可以调整到零,在这种情况下,单元格只能实现单个tap和一个新的数据样本将在每个时钟到达。 在这种情况下,只有第一个寄存器和锁存器在分别使用shift_register和latch_file(select)总是为0001),并且每个都有新的数据输出时钟。
基本单元可以布置在允许的拓扑中适用于各种配置。 图5显示了一个拓扑这可以用于八个单元格。 为清楚起见,滤波器系数输入到基本单元省略。 取决于多路复用器的设置和数量每个单元实现的抽头,一些可能的配置对于电路来说,
1.四个独立的过滤器(每个2个单元格),2到8个
(sel1 = 1,sel2 = 1,sel3 = 1);
2.两个独立的过滤器(每个4个单元),4到
每个16个抽头(sel1 = 0,sel2 = 1,sel3 = 0); 要么
3.具有8到32个抽头的一个滤波器(8个单元)(sel1 = 0,
sel2 = 0,sel3 = 0)。
对于第一个配置,所有x输入和y输出都是用过的。 然而,对于第二种配置,x0和x2是输入和y1和y3分别是输出。 对于第三个配置,x0是滤波器输入,y3是滤波器输出。 各种配置可能性允许相同的硬件在许多不同的设计中被使用的情况。
图5.基本单元拓扑结构示例
表2.串联两个电池的操作(图5)
使用两个单元格实现的过滤器的操作与图5的顶部两个单元一样,系列如图所示表2.列y0和y1表示该值y输出分别为第一和第二单元。 因此,y0连接到第二个单元格的yprev。 假设两者单元被配置成实现四个抽头,所以这两个单元格过滤器共有8个抽头。 与表1不同,表2表示4个时钟周期,或单个采样期。 显示的值是样品末端的值期间(每四个钟)。 假设滤波器系数h0到h3和h4到h7已经存在分别加载到第一和第二单元的latch_file中。再次,d0,d1等代表输入数据样本。
虽然我们有一个连锁的两个电池实现八抽头,采样周期与单个采样周期相同单元实现四个水龙头,如表所示抽头的数量虽然翻了一番,但是样本周期保持在四个时钟周期。 的确,表演的基于细胞的方法不依赖于链中的细胞数。 这个特点是其中之一使用基于细胞的方法的主要优点,并允许设计容易地缩放为较大的滤波器没有采样率损失。
注意在表2中,当新的输入样本进入时过滤器,过滤的输出在末尾不可用抽样期。 相反,过滤的输出变得可用在以下抽样期结束时。 因此,这个方法引入了额外的延迟周期。运用前面讨论的平行或顺序方法,过滤输出在相同的末尾可用输入到达的采样周期 - 延迟一个采样周期。 使用基于细胞的方法,为每个额外的单元添加额外的延迟周期它被放在链中。
额外的等待时间是基于蜂窝基的主要缺点做法。 对于需要很多的很长的过滤器电池串联,延迟时间可能太长,关键的实时应用程序。 但是,大多数应用程序可以容忍增加延迟的交换更高的采样率和更大的数据吞吐量。 的当然,这个缺点可以通过实现来消除一个加法器的二叉树,全局总结结果每个单元格在每个采样周期结束时。 不过这个类型的方法会引入大量的硬件的复杂性和消除的容易程度可以缩放基于单元格的方法。
对于图4所示的单元格,关键路径来自于控制器通过三态缓冲区到乘法器、加法器,多路复用器,最后是累加器寄存器。 就这样电池的时钟周期是,
CellPeriod =DelayBuffer DelayMult DelayAdd DelayMux (6)
再次,设置和保留时间已被忽略。
每个单元必须对其实现的每个过滤器抽头进行一次循环并且链中的每个单元格添加了另外的样本潜伏期。 对于特定的细胞链,采样率和延迟由下式给出,
SampleRate = 1/([Taps /Cells] times;CellPeriod ) (7)
Latency = Cells(eacute; Taps Cellsugrave; times;CellPeriod) (8)
其中细胞pound;(7)和(8)都可以抽出pound;4times;细胞。
如果每个单元格仅用于实现一个水龙头,则以单元为基础方法的采样率将与之相似并行方法。 由于每个单元格都用于实现更多的水龙头,采样率将接近顺序做法。 因此,不仅能够实施使用相同单元
剩余内容已隐藏,支付完成后下载完整资料
资料编号:[141378],资料为PDF文档或Word文档,PDF文档可免费转换为Word

