
英语原文共 16 页,剩余内容已隐藏,支付完成后下载完整资料
唇读的视觉特征提取
Iain Matthews, Member, IEEE, Timothy F. Cootes, Member, IEEE, J. Andrew Bangham, Member, IEEE, Stephen Cox, Member, IEEE, and Richard Harvey, Member, IEEE
摘要:语言的多模态性质在人机交互中经常被忽略,但是唇部变形和其他身体运动(例如头部的运动)传达了额外的信息。 我们整合来自许多来源的语音提示,这提高了可懂度,特别是当声学信号降级时。 本文展示了这种额外的,通常是互补的视觉语音信息如何用于语音识别。 比较了使用隐马尔可夫模型参数化唇图像序列以进行识别的三种方法。 其中两种是自上而下的方法,它们适合内唇和外唇轮廓的模型,并分别从形状或形状和外观的主成分分析中得出唇读特征。 第三种自下而上的方法使用非线性尺度空间分析直接从像素强度形成特征。 所有方法都在隔离字母的multitalker视觉语音识别任务上进行比较。
索引术语 - 视听语音识别,统计方法,主动外观模型,筛子,连接形态。
1、介绍
自17世纪以来,已有文献记载了在说话者的面部动作中传达有关语音的有用信息[19],听力受损的听众能够非常成功地使用唇语识别技术,并且许多人能够理解流利的口语。 然而,即使对于那些听力正常的人来说,能够看到说话者的面部也可以显着提高可读度,特别是在嘈杂的条件下[36], [66], [68], [81],在音频域中容易混淆的一些语音(例如,“b”和“v”,“m”和“n”)在视觉域中是不同的[82], [85]。此外,有证据表明视觉信息用于补偿音频信号中易受声学噪声影响的元素,例如,关于发音位置的线索[82]。人类识别中的音频和视觉感知域之间的密切关系可以通过视听幻觉来证明,例如McGurk效应[57], [62],其中感知者“听到”由于冲突的视觉刺激的影响而在声学上所说的东西之外的东西。
这些观察结果提供了在计算机语音识别系统中尝试将视觉与语音结合的动机,Petajan[70提出了视觉可以改善语音识别的早期证据,他使用当时的动态时间扭曲技术和口腔开放的视觉特征,并表明视听系统优于单独的语音或视觉。其他人从静态图像映射功率谱89],或使用光学流[58]作为视觉特征并获得类似的结果。在20世纪80年代中期,隐马尔可夫模型(HMM)[51]的发展提高了语音识别的准确性,并使大词汇量识别成为可能。HMM首先应用于使用Petajan口腔提取硬件的扩展[38]的Goldschen视觉语音识别,从那时起,许多方法已应用于视觉和视听语音识别。最近的评论可以在[22],[39],[44]中找到.
目标是结合声学和视觉语音提示,使识别性能遵循人类特征,双峰结果始终优于单独使用任何一种方式[1], [76],这个问题有三个部分:
1.来自音频信号的语音识别,
2。显着视觉特征的识别和提取,以及
3.音频和视觉信号的最佳集成
这些问题中的第一:,音频语音识别,现在“解决”到在个人计算机上运行的语音识别系统广泛且廉价可用的程度,虽然它们对不同扬声器,重音,麦克风,干扰信道或环境噪声等因素的稳健性有待提高;第二个问题,即从图像序列中提取视觉特征[9],[15],[17],[33],[39],[44],[48],[55],[58],[65 ],[71],[79],[87],[89],这里解决的问题与第三个问题,音频和视觉信号的整合[1],[30],[40],[76] ,[82]。初步报告[61]使用96个话语的“Tulips”数据库,而不是这里使用的780,以提供更好的机会来辨别正在开发的方法之间的差异.
产生视觉特征的主要问题是视频序列中的大量数据,这是所有计算机视觉系统共同的问题。 每个视频帧包含数千个像素,必须从中提取大约10到100个元素之间的特征向量.
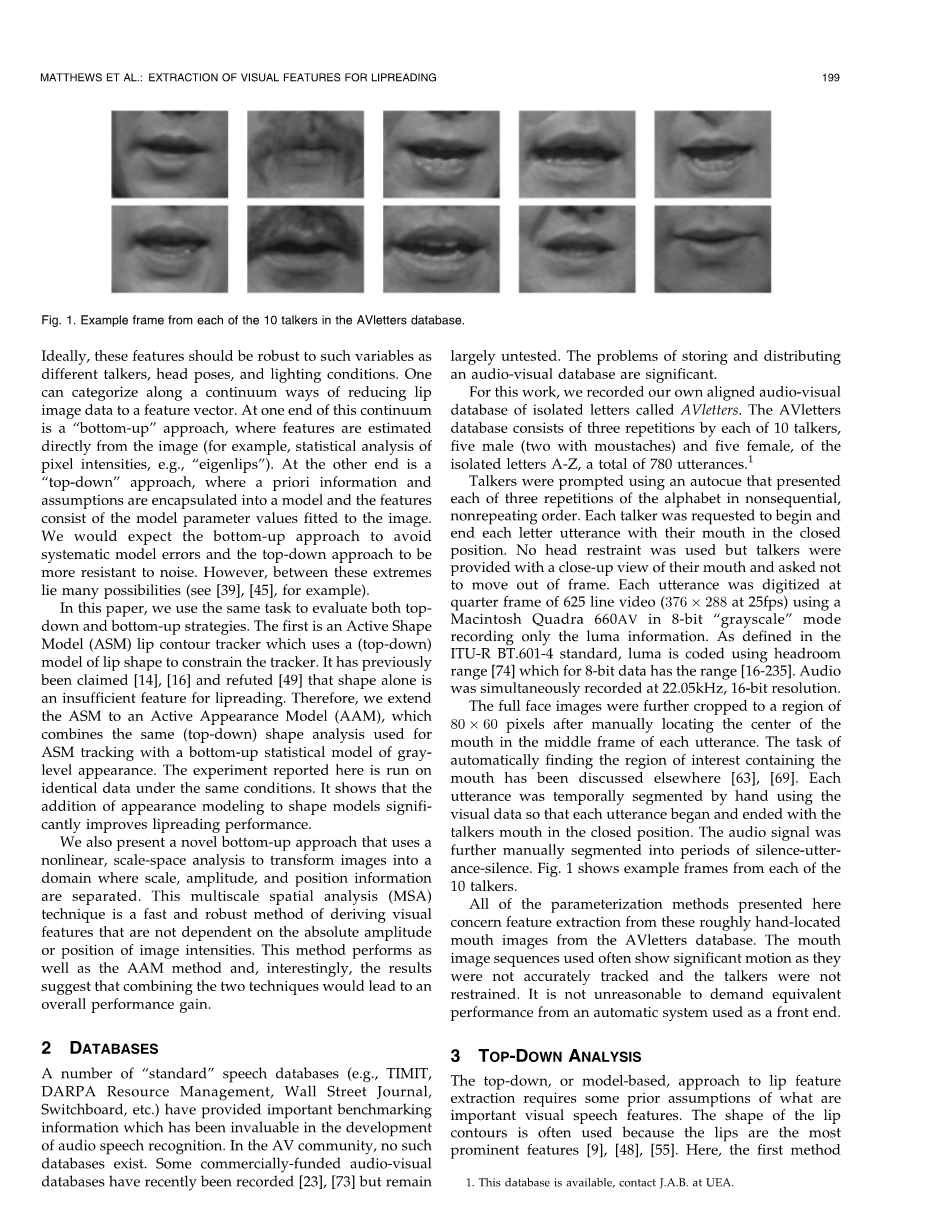
Fig 1.来自AVletters数据库中的10个谈话者中的每一个的示例帧
理想情况下,这些特征应该对诸如不同的谈话者,头部姿势和照明条件等变量具有鲁棒性。人们可以沿着将唇图像数据减少到特征向量的连续方式进行分类。 在该连续体的一端是“自下而上”方法,其中直接从图像估计特征(例如,像素强度的统计分析,例如“本征片”)。另一端是“自上而下”的方法,其中先验信息和假设被封装到模型中,并且特征由适合图像的模型参数值组成。我们希望自下而上的方法可以避免系统模型误差,而自上而下的方法可以更好地抵抗噪声, 然而,在这些极端之间存在许多可能性(例如,见[39],[45])。
在本文中,我们使用相同的任务来评估自上而下和自下而上的策略, 第一种是活动形状模型(ASM)唇形轮廓跟踪器,它使用(自上而下)唇形模型来约束跟踪器。先前已经声称[14],[16]并驳斥[49],单独的形状是唇线不足的特征。因此,我们将ASM扩展为主动外观模型(AAM),该模型将用于ASM跟踪的相同(自上而下)形状分析与灰度外观的自下而上统计模型相结合。此处报告的实验在相同条件下运行相同的数据,它表明,在形状模型中增加外观建模可以显着提高唇线性能。
我们还提出了一种新颖的自下而上方法,该方法使用非线性尺度空间分析将图像转换为分离比例,幅度和位置信息的域。这种多尺度空间分析(MSA)技术是一种快速且稳健的方法,用于导出不依赖于图像强度的绝对幅度或位置的视觉特征。该方法与AAM方法一样有效,并且有趣的是,结果表明结合这两种技术将导致整体性能提升。
2、数据库
许多“标准”语音数据库(例如,TIMIT,DARPA资源管理,华尔街日报,交换机等)已经提供了重要的基准信息,这在音频语音识别的发展中是非常宝贵的。在AV社区中,不存在这样的数据库。最近已经记录了一些商业资助的视听数据库[23],[73]但仍未进行大量未经测试。存储和分发视听数据库的问题很重要。
对于这项工作,我们录制了自己的对齐视听数据库,其中包含名为AVletters的孤立字母。 AVletters数据库由10个讲话者,5个男性(两个带胡须)和5个女性中的每一个重复组成,其中孤立字母A-Z,总共780个话语。
使用自动提示来提示谈话者,该自动提示以非连续的,非重复的顺序呈现字母表的三次重复中的每一次。要求每个说话者在闭合位置开始和结束每个字母的发音。 没有使用头枕,但是谈话者可以近距离观察他们的嘴巴并且要求不要移出框架。 每个话语在625行视频(376 288,25fps)的四分之一帧上使用Macintosh Quadra 660AV以8位“灰度”模式进行数字化,仅记录亮度信息。 根据ITU-R BT.601-4标准的定义,亮度使用余量范围[74]进行编码,对于8位数据,其范围为[16-235]。 音频以22.05kHz,16位分辨率同时录制。
在手动地将嘴的中心定位在每个话语的中间框架中之后,将全脸图像进一步裁剪到80times;60像素的区域。 自动找到含有口腔的感兴趣区域的任务已在其他地方讨论过[63],[69]。 使用视觉数据手动地对每个话语进行时间分割,使得每个话语在谈话者嘴巴处于闭合位置时开始和结束。 音频信号被进一步手动分割成静音 - 话语 - 沉默的时段。 图1示出了来自10个谈话者中的每一个的示例帧。
这里介绍的所有参数化方法都涉及从AVletters数据库中这些大致手动定位的嘴图像中提取特征。 所使用的嘴部图像序列通常显示出显着的运动,因为它们没有被准确地跟踪并且说话者没有被约束。 要求用作前端的自动系统具有相同的性能并非不合理。
3、自顶向下分析
自上而下或基于模型的唇部特征提取方法需要先前假设什么是重要的视觉语音特征。 唇部轮廓的形状经常被使用,因为嘴唇是最突出的特征[9],[48],[55]。这里,报告的第一种方法使用活动形状模型(ASM)来跟踪内唇和外唇轮廓并提供一组控制结果。 ASM首先在[27],[28]中制定,并应用于[54],[55]的唇读。 我们使用的第二种自上而下的方法利用了ASM [26]的最新扩展,它将统计形状和灰度级外观结合在一个统一的主动外观模型(AAM)中。
Fig 2 .内外轮廓唇模型。 白点代表主要和次要地标。 线条表示每个点的法线。
3.1、主动形状模型
活动形状模型(ASM)是一种形状约束的迭代拟合算法[28]。 形状约束来自使用统计形状模型,也称为点分布模型(PDM),其从手工标记的训练数据的统计获得。 在本申请中,PDM描述了在训练数据意义上缩小的有效唇形空间,并且该空间中的点是唇形的紧凑表示,可以直接用作唇线的特征。
从一组训练图像计算点分布模型,其中已经定位了界标点。 在这里,通过眼睛定位了标志点,但这可能是自动化的[46]。 每个示例形状模型由其标志点的(x,y)坐标表示,其在所有训练示例中具有相同的含义。 使用的内唇和外唇轮廓模型如图2所示,有44个点(外部24个点,内部轮廓20个)。
在图2中,主要标志是操作员可以可靠定位的那些,并且次要标志随后在主要点之间等间隔。 为了减少定位误差,使用样条插值对次要点进行平滑。
如果第i个形状模型是
然后两个相似的形状x1和x2通过最小化对齐,
其中x和的比例,s,旋转和平移的姿势变换是,
Fig 3.点分布模型。 每种模式在平均值plusmn;2处绘制。 七种变异模式描述了所有10个说话者的字母A,E,F,M和O的训练集的95%的方差。
W是每个点的对角线权重矩阵,其权重与每个点的方差成反比。
为了对齐训练模型集,使用传统的迭代算法[28]。 给定一组对齐的形状模型,可以计算平均形状xs,并且可以使用主成分分析(PCA)确定描述关于平均形状的大多数方差的轴。 然后可以通过将这些模式的缩减子集t添加到平均形状来近似任何有效形状,
其中Ps是第一个特征向量的矩阵,
和bs是t权重的向量,由于特征向量是正交的,因此形状参数bs也可以从一组示例点xs计算
这允许有效的唇形在紧凑的,统计上导出的形状空间中表示。 变化模式的数量比使用的界标点的数量少得多,因为选择界标点的数量以清楚地定义唇形并且它们高度相关。 没有PCA缩放问题,因为所有变量都是方形图像坐标轴中的x或y值。 选择PDM的顺序,使得协方差矩阵的第一个特征值描述总方差的95%。
根据AVlet数据库的1,144手标记训练图像计算的PDM中的前六个(七个)模式如图3所示。所有10个A,E,F,M和O的第一个话语的所有帧。 谈话者被用作训练数据。 每种模式都绘制在相同轴上的平均值的正负两个标准偏差处。
Fig 4.GLDM的前三种模式。 每种模式在平均值plusmn;2处绘制。
为了将PDM与示例图像进行交互式配合,需要适合度或成本函数。 这里,使用来自形状模型的每个点的法线的级联灰度级轮廓的统计模型[43],[54],[55]。 这允许PCA用单个统计模型表示形状模型的所有灰度法线,并因此考虑不同点处的灰度级轮廓之间的相关性。 图2绘制了关于每个模型点的11像素长度的法线。 在此示例中,连接的灰度级配置文件形成44*11=484个长度向量。 与PCA用于计算PDM的方式相同,可以计算灰度分布模型(GLDM),
还选择GLDM的顺序,使得t模式描述95%的方差。 对于AVletters数据库,GLDM有71种模式。
GLDM的前三种模式如图4所示,平均值为plusmn;2个标准偏差。 GLDM仅在每个界标点处模拟单个像素宽度法线。 为了辅助可视化,轮廓已经加宽并且图像平滑以呈现全口图像的外观(参见图4)。
与PDM(5)一样,可以计算给定级联灰度级轮廓矢量的模型权重矢量,
原始ASM算法[27],[28]模拟每个单独的界标点的灰度级轮廓,并通过逐点计算模型更新来迭代地拟合特定图像。 这里,使用更简单的拟合算法。 组合的姿势和形状参数形成下坡单纯函数最小化的变量[54],[55]。 单纯形算法[67]不需要计算误差曲面的梯度,但可能需要多次迭代才能收敛到局部最小值。
此算法中使用的成本函数计算GLDM的平方和误差,并且衡量当前模型点的灰度级配置文件与手动点的训练集中的灰度级配置文件的匹配程度。 在每次迭代时,对单形中的每个点评估成本函数,理想情况下,仅在正确的模型形状和位置处具有最小值。
可以使用(7)针对特定的级联轮廓向量xp计算权重参数bp,以找到给定GLDM(6)的当前级联灰度级轮廓的最佳近似。由于近似, 仅使用GLDM的tp模式引入了一些误差,
并且模型和轮廓之间的平方和误差是
使用图像中心的平均形状初始化拟合过程,零旋转和单位标度。 通过在x和y方向上的五个像素的平移,通过0:1弧度的旋转,将单纯形初始化为扰动,具有10%的比例增加,并且对于七个模式中的每一个,标准偏差为0:5 PDM的变异。当单形中最大点和最小点处的成本函数的比率小于0.01时,获得收敛。仅使用单形最小化姿势和形状矢量的形状参数作为唇读特征。 图5绘制了用于字母序列D-G-M上的跟踪结果的PDM的七种变化模式中的每一种的方向。
3.1.1每个讲话者建模
数据库中谈话者外观之间的巨大差异,如图1所示,意味着GLDM在整个数据库中的训练有很多模式。 在这样的高维空间中评估的成本函数(9)不太可能具有明显的最小值,并且单面局部搜索将不能找到讲话者嘴唇的正确姿势和形状。解决方案是为每个讲话者建立单独的GLDM。 这些只需要对单个讲话者的
剩余内容已隐藏,支付完成后下载完整资料
资料编号:[20590],资料为PDF文档或Word文档,PDF文档可免费转换为Word
课题毕业论文、外文翻译、任务书、文献综述、开题报告、程序设计、图纸设计等资料可联系客服协助查找。

