
英语原文共 6 页,剩余内容已隐藏,支付完成后下载完整资料
用于字符识别和分割的2D马尔可夫模型
Sylvain Chevalier, Edouard Geoffrois and Francoise Preteux
lowast;: ARTEMIS project Unit, GET/INT, Evry - France
lowast;lowast;: Centre drsquo;Expertise Parisien, DGA/DET/CEP, Arcueil - France
摘 要:处理多媒体内容中的文本组件仍然是文档索引的一个挑战性问题检索和检索。 更具体地说,手写字符处理是模式识别的一个非常活跃的领域。本文描述了一种用于字符识别和分割的创新二维方法。该提出的方法结合了马尔可夫建模,有效的解码算法和窗口化的频谱特征提取方案。 实现严格的评估方法来分析和讨论性能,用于数字和单词识别的数字。
关键词:手写识别,Markov随机字段,2D动态编程。
- 介绍
手写分析已经通过应用各种方法进行[8]。地理度量方法[13]很容易实现,但是其整体性是一个严重的限制。手写词语分析可以用有效的方式进行有效处理基于Markov的一维统计方在受限制的任务中获得良好结果[9]。但是,手写的2D本质是显而易见的,但没有完全令人满意的2D方法:统计模型,如伪2D [6]和因果2D模型[12]试图解决这个问题,但是它们受到方向独立性的限制和因果假设。
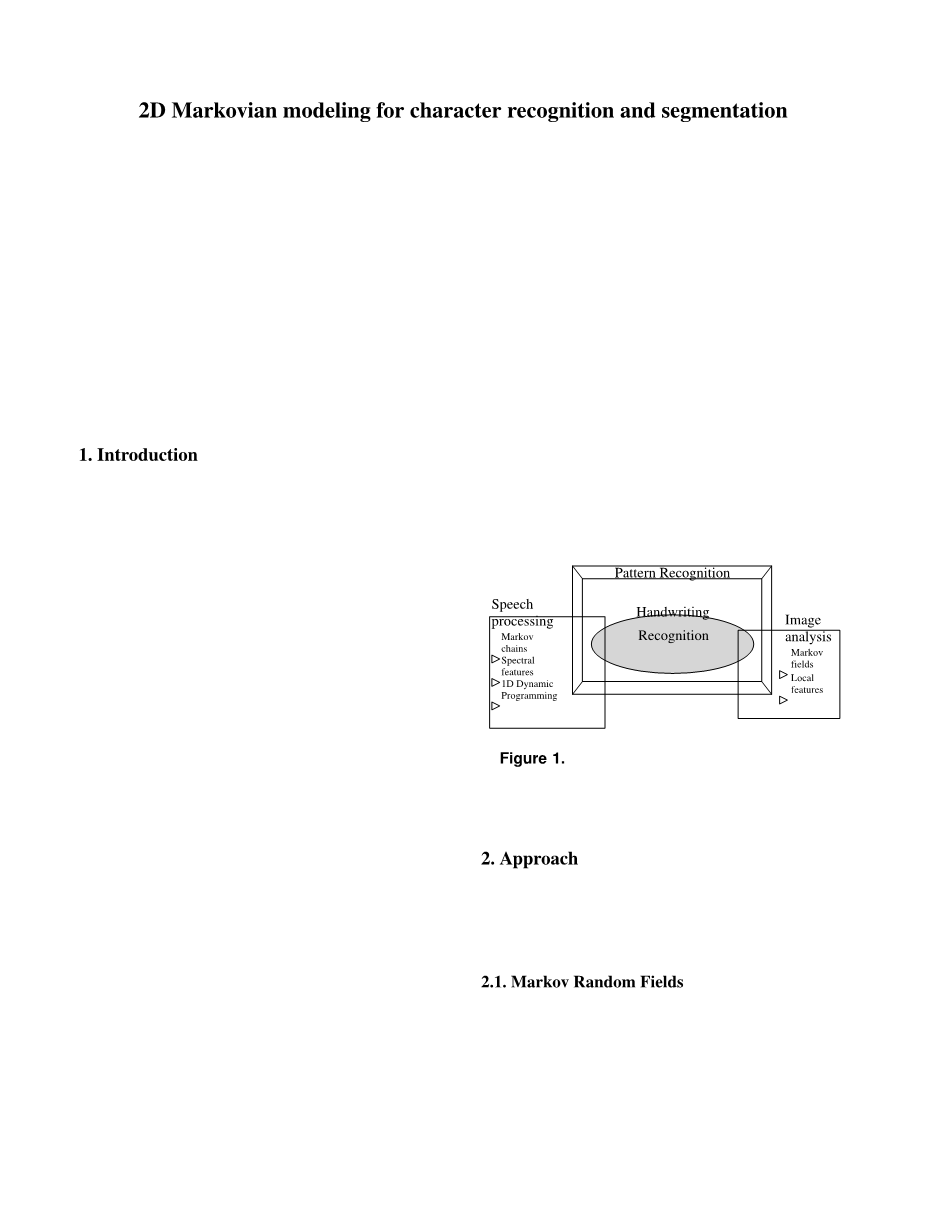
我们提出了一种完全2D手写识别方法,可应用于文档处理的每一步,并将其应用于手写数字和手写文字识别。 大多数所执行的技术都是众所周知的但是所提出的组合是原始的。马尔可夫链,谱特征和动态规划已经成功地用于语音处理,而马尔科夫随机场模型化和局部特征提取是图像分析的关键工具。这些相互作用的概要如图1所示。第2节介绍了我们的方法的主要理论背景,而第3节介绍了如何这些原则适用于数字识别任务。第4节将所提出的方法扩展到手写单词识别。 第5节总结了论文和为改进和扩展开辟了新的视角提出的二维马尔可夫模型。
图1.手写识别,图像分析和语音处理之间协同作用的概要。
- 方法
我们的方法框架是基于马尔可夫模型,这是流行的模式识别统计模型。
2.1.马尔可夫随机场
马尔可夫模型被广泛用于各种模式识别问题[3]。 它基于短期依赖的马尔可夫假设这对于在计算机视觉中遇到的大多数图像似乎是有效的。
在这种情况下,图像I是一组网站(i,j)与标签相关omega;i,jisin;S,其中S = {s1,s2,...,sN}是模型的状态集合。 区域R是一个子集一幅图像的相邻位置,以及相关的一组图像标签是区域omega;R的配置。马尔可夫假设假设,网站之间的密切关系减少到本地一:
P(omega;i,j | omega;I(i,j)) = P(omega;i,j | omega;N(i,j)), (1)
其中N(i,j)是与之相邻的站点集合(i,j)。 如果对每一对都是N,则N是一个相邻函数站点(i,j)和(k,l),
(i, j) isin; N(k, l) hArr; (k, l) isin; N(i, j). (2)
处理邻近关系的一种便利方式是使用派系:派系是一组邻居的网站。 在4连通中,派系对应于单个站点和一对垂直和水平的网站。有了这种形式主义,就可以使用Gibbs分布相当于马尔可夫随机场[1]:
P(omega;) = 1/Z *exp(minus;Sigma;cisin;C* Vc(omega;)) (3)
其中C是集合集合,Vc是与集合c相关的潜在函数,Z是归一化常数使得Pomega;P(omega;)= 1。
隐马尔可夫随机场(HMRF)是一类具有观察层的马尔可夫场。 每个站点的图像与可以观察的图像相关联是数字还是矢量。 让我们表示观察到的图像O = {oi,j}。 仅观察一个站点取决于隐藏的隐藏状态:
P(O | omega;) = Yi,j*P(oi,j | omega;i,j). (4)
寻找最佳配置的问题简化为寻找omega;的问题,最小化:
U(omega;) = Sigma;(i,j)minus; log(P(o(i,j) | omega;(i,j))) Sigma;cisin;C*Vc(omega;). (5)
2.2.解码算法
给定一个马尔科夫模型,解码程序旨在为网站分配标签。 给定模型的参数,确定最优配置如:
omega;circ; = arg maxomega;P(O | omega;). (6)
已经提出了几种方法来执行此操作最大化如模拟退火[4],其中是非常缓慢的,或迭代条件模式(ICM)[2],这给出了次优解决方案。 限制性更强假设,如马尔可夫模型中的因果关系可以将解码降低到1D的问题用动态规划很容易解决[11]。 更多最近,动态规划的延伸到了多维情况已经提出[5]并且可以很容易应用于马尔可夫随机的解码场。 这项工作是2D动态规划(2DDP)算法首次应用于手写承认。
让我们考虑将图像分割成两个区域R1和R2。 设part;R1和part;R2为边界这些地区,即属于派系的地点包含来自两个不同地区的网站(图2)
图2.将图像分为两个区域(R1和R2)可以分成多个子区域。 只有代表属于边界的站点。
对于给定的配置omega;,令omega;1,omega;2,part;omega;1和part;omega;2成为这种配置的限制R1,R2,part;R1和RR2。 最小化U的功能可以用两个地区的不同条款来书写和一个互动术语我相关的网站的边界。
U(omega;) = U(omega;1) I(part;omega;1, part;omega;2) U(omega;2).
符号U(omega;1)和U(omega;2)是UR1(omega;1)和UR2(omega;2)的简化符号,对应于U(omega;)的条件仅取决于一个区域。术语I(part;omega;1,part;omega;2)是简化的符号Ipart;R1,part;R2(part;omega;1,part;omega;2)并对应于剩余的与跨越边界的派系有关。
让我们考虑两个配置omega;和omega;在边界上具有相同的配置(即(part;omega;1,part;omega;2)=(part;omega;1,omega;2))。 在这种情况下,我们有:
U(omega;1) lt; U(omega;1′)
} rArr; U(omega;) lt; U(omega;′).
U(omega;2) lt; U(omega;2′)
因此,对于给定的边界配置(part;omega;1,part;omega;2),可以看出:
omega;circ;1 = arg min U(omega;1)
}rArr; omega;circ;1cup;omega;circ;2 = arg min U(omega;1cup;omega;2),
omega;circ;2 = arg min U(omega;2)
于是,
omega;circ; = omega;circ;1 cup; omega;circ;2.
因此,对于每个omega;1和omega;1计算总和U(omega;1) I(omega;1,omega;2) U(omega;2)是没有必要的,并且omega;2找到最佳配置。 只有最佳配置omega;1和omega;2必须存储每个配置边界part;omega;1和part;omega;2。
假设part;Omega;r(r = 1,2)是区域Rr边界的可能配置集合,并且Omega;r= {omega;r/part;omega;risin;part;Omega;r}的最优配置网站内的每个网站的配置边界。 全局最优omega;通过组合Omega;1和Omega;2的配置和选择来获得最低:
omega;circ; = arg min(omega;circ;1,omega;circ;2)isin;Omega;circ;1times;Omega;circ;2U(omega;circ;1) I(part;omega;1, part;omega;2) U(omega;circ;2).
这个过程可以迭代:Omega;1可以被计算
从Omega;1.1和Omega;1.2以相同的方式。只有一部分R1.1和R1.2的边界仍然处于新的状态区域R1的边界(图2中灰色)。在每个步骤中,对于区域Rr,可以计算Omega;r来自两个子区域的最佳配置Omega;r.1和Omega;r.2,依此类推,直到基本到达一个站点的区域。此时,初等区域可以被初始化为N中的任何一个状态。从一组基本地区来看,地区是合并两个和两个,只保留每个界配置的最佳配置,直到完成整个图像在一个地区。区域合并的顺序(称为合并策略)可以是任何类型。它不会影响结果,但会影响计算成本。对于一个mtimes;n的图像,考虑到每个配都会产生Nmtimes;n的计算成本。使用2DDP,如果地区是逐行合并的,那么成本将是(mtimes;n)times;Nm。在实践中,这个数字通常太高,但修剪策略可能会降低这通过消除不太有希望的成本来达到一个容易理解中间配置的区域。
2.3.特征提取和观测密度建模
观察O的值直接从原始图像中提取。 文献中已经提出了很多种特征提取类型,它们高度依赖于所使用的模型化类型[13]。在HMRF建模的背景下,必须提取2D局部特征。 对图像进行窗口化分析可以提取表示为矢量的观察结果。 我们使用完全连续的二维窗口光谱特征提取,并提取关于图像中主要方向的信息。 它包括计算一个窗口中的二维傅里叶变换(用二维高斯窗口调整)并提取模块和相位中的选定系数。 第一个系数(即位于所得图像中心附近),低频系数保存笔画和方向的信息。 图3给出了这个过程的一个例子。
图3. 2D光谱局部特征提取
对于每个状态s,P(o | s)是用高斯混合有效存储的观测密度。 这些混合物可以适用于任何实际的分布。 EM算法能够有效地从一组样本中计算参数。 我们有:
P(o|s) =MSigma;i=1 kiG(o, micro;i,omega;, Sigma;i,omega;),
其中G(o,mu;,Sigma;)是平均值mu;和协方差矩阵Sigma;(实际上是对角矩阵)的高斯函数的o中的值,并且其中PiM = 1 ki = 1。 在图4中可以看到相应的高斯混合物。
图4.具有相应的高斯混合的实分布。
- 应用于手写识别
处理短期词汇任务(如数字识别)的最简单方法是执行识别的模型判别方法:
C = arg maxckP(ck | O) = arg maxckP(O | ck)P(ck).
在观察到O的情况下,C是该ck中最可能的类型。 如果我们有这些ck的一组模型,2DDP可以执行P(O | ck)的计算。 概率P(ck)可从训练集的统计数据中获知。因此,剩余的问题是数据库的选择,HMRF的状态空间,2DDP合并策略和模型训练策(观察密度和潜力集合)的选择。
3.1. 数据库
MNIST数据库[10]是一个广泛使用和公开可用的手写数字数据库。 从数据库中提取的几个样本可以看到图5有一套60,000个样本的训练集和10000个样本的测试集。 为了开发和调整算法,我们将训练集分为开发集和验证集,这样我们只对测试集进行很少的评估。 对测试集执行更多评估将包括将测试集中的知识纳入算法中,并给出不完全符合实际的结果。 对于第i类,验证集是训练集的最后ni个样本,其中ni是相应测试集中的样本数。
图5.来自MNIST数据库的样本
3.2状态空间
为了捕捉角色的形状,模型必须保存笔画的信息,特别是它们的方向和相对位置。 为了捕捉这些信息,状态可以与图像中笔划的均匀部分相关联。 中描述的功能第2.3节有效地提取方向上的局部特征。 潜能(参见2.1节)可以保存关于这些笔画相对位置的信息。图6说明了对状态的预期分割。 根据位置和斯托克斯方向,35个状态中的每一个都与图像的均匀部分相关联。 在我们的实验中,5times;7状态模型给出了最好的结果,因为可以预期关于数字8的形状。
图6.将样本图像预期分成35个状态
3.3. 合并策略和修剪策略
如第2.2节所述,合并政策不应对结果产生任何影响,而应对计算成本产生影响。 实际上,真正的2DDP解码是不容易的,所以必须执行修剪策略。 它包括消除不太有前途的配置可能会导致次优的最终配置。 这个原理被称为在马尔可夫链和一维动态规划的语音处理中非常有效[7]。在这种情况下,配置消除后,重要的是首先要合并不确定性不重要的区域。 我们的合并策略首先合并图像外部边界上的网站,然后合并更接近中心的网站。 图7给出了这种合并策略的例子。
图7.合并策略:首先合并外部站点
3.4. 特征系数
相关系数从傅里叶变换中选择。 阶段和模块都保留重要的信息。 因为不同的窗口重叠,所以不需要为每个像素计算矢量。 我们发现使用10维矢量的14times;14图像可以得到很好的结果(参见3.6节)。图8说明了从傅里叶变换中提取的第一个系数,或者是模块和相位。
图8.特征提取的第一个系数,或者模块和相位。
3.5. 学习策略
为了执行数字样本的识别,必须有一组模型可用。数字模型由一组观察密度函数(每个状态一个)以及一组潜力集合组成。这个数据库的可用基本事实归结为样本的类别,因此没有可用的训练集的分割信息。通过1D问题来解决这个问题的一种常见和有效的方法是执行维特比学习,该简化是简化的EM方法,其中只有最优配置被保留用于计算期望[7]。第一个模型通过使用训练样本的规则分割成35个状态来计算。这些第一次分割允许计算初始模型(观察密度和转换概率)。然后使用这些模型来处理2DDP解码并获得新的分段,这将给出新的模型参数。这个过程然后迭代直到收敛。这种学习策略如图9所示。
图9. 2D维特比学习
3.6. 结果
表1总结了不同类型特征向量的验证集的结果以及测试集上的最终结果。 这些结果没有排斥过程。 我们算法的处理速度在单个处理器上约为每秒3个样本。
表1.不同类型的特征向量的错误率
- 扩展到手写单词识别
这种提出的方法非常一般,可以很容易地应用于各种识别和分割任务。 在本节中,我们提出了手写单词识别的扩展。 用于这些第一次词语实验的数据库是Senior&Robinson数据库。 它是由一位撰稿人写成的25个手写页面,并分成单词。 将我们的方法扩展到文字处理的一种简单方法是通过拼接字母模型来建立单词模型。为词汇表的每个单词建立一个模型,但这与整体方法不同,因为只有字母模型被训练。这个想法是用一个连接过程来建立单词模型,其中转换概率在右边的状态第一个字母和第二个字母左侧的状态。这个过程可以迭代来建立任何单词模型。一旦单词图像被分割成状态,可以根据这种分割将图像切成字母,然后可以使用该组字母图像来训练字母模型,如第3节所述。我
剩余内容已隐藏,支付完成后下载完整资料
资料编号:[23366],资料为PDF文档或Word文档,PDF文档可免费转换为Word

